
![]()
![]()
A new QuEval paper has been accepted at RCIS 2014 issuing the challenge of managing the large amount of tailored index implementation variants: Toward variability management to tailor high-dimensional index implementations.
Multimedia data, or high-dimensional data in general, have been subject to research for more than two decades and gain momentum even more in the communication technology age. From a database point of view, the myriads of gigabyte of data pose the problem of managing these data. In this course, query processing is a challenging task due to the high dimensionality of such data. In the past, dozens of index structures for high-dimensional data have been proposed and some of them are even standard-like references. However, it is still some kind of black magic to decide which index structure fits to a certain problem or outweighs other index structures. In particular, the following questions have to be answered to make a decision in favor or against a certain index structure:
This is where QuEval, a framework for quantitative comparison and evaluation of high-dimensional index structures comes into play. QuEval is a Java-based framework that supports comparison of index strucutres regarding certain characteristics such as dimensionality, accuracy, or performance. Currently, the framework contains of six different index structures. However, a main focus of the framework is its extensibility and we encourage people to contribute to QuEval by providing more index structures or other interesting aspects for their comparisons.
QuEval is under constant development. The following features are implemented:
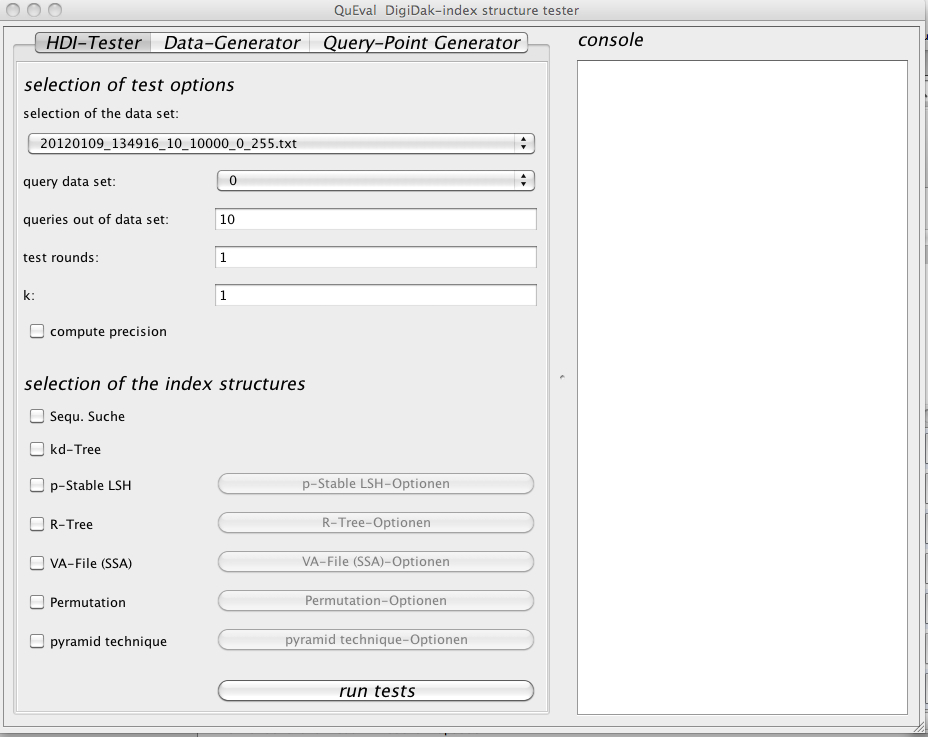
Generally, our framework consists of three parts: Data Generator, Query-Point Generator, and HDI Tester. In the following we describe briefly each of these components and how they interact (which is also indicated by the figure below).

Data Generator: This component is responsible for generating the data set that is used for a certain scenario. To this end, the user can specify certain characteristics of the data. In particular, we currently support the specification of dimensionality (i.e., number of dimensions), the amount of data (i.e., number of data points in the data set), the stochastic distribution of data, and the range of values for each dimension. Furthermore, it is possible to save the generated data set and thus, reuse it for replicating or extending a former scenario.
Query-Point Generator: Analogously, this component is responsible for generating the query points used within a scenario. This can be done in two different ways: First, this component takes the generated data set as input and selects randomly a specified number of query points out of this data set. Consequently, the query points exhibit the same properties as the data points in the data set. Alternatively, the Query-Point Generator can generate query points independent of the underlying data set (nevertheless, with the same properties). Furthermore, the generated query points can be saved and reused for replication.
HDI Tester: This is the core component of our framework since it performs the actual comparison of index structures. To this end, the user has to specify a scenario description, containing the following information:
The user can create this scenario description by means of a graphical user interface. To compare/evaluate the selected indexes, the HDI Tester determines the accuracy (only if chosen) and time efficiency. In the case that the framework computes the accuracy (currently based on the euclidean distance), it uses the sequential scan to determine the correct query response and compares this result to the query result of the evaluated index structures. The results of a scenario are saved in a CSV file that can be deployed for detailed analyses of the experimental results.
| Name | Further information/original papers | Link(s) |
|---|---|---|
| Pyramid technique | Original paper: S.Berchthold et al., The pyramid-technique: towards breaking the curse of dimensionality, SIGMOD Records, 1998 Implementation based on: D.-H. Lee et al., An efficient technique for nearest-neighbor query processing on the SPY-TEC, Trans. Knowl. Data Eng., 2003 |
paper access paper access |
| VA-File | Original paper: R.Weber et al., An approximation-based data structure for similarity search, technical report, 1997 | paper access |
| Prototype-based approach | Original paper: E.C.Gonzalez et al., Effective proximity retrieval by ordering permutations, Trans. Pattern Analysis and Machine Intelligence, 2008 | paper access original implementation (in C#) |
| LSH-based approach | Original paper: P.Indyk et al., Approximate nearest neighbors: towards removing the curse of dimensionality., ACM SAC, 1998 Implementation based on: M.Data et al., Locality-sensitive hashing scheme based on p-stable distributions, Int. Symp. on Comp. Geometry, 2004 | paper access paper access |
| R-Tree | Original paper: A.Guttman, A dynamic index structure for spatial searching, SIGMOD, 1984 Original implementation from the GeoCraft open source framework; adjusted in order to add exact match functionality to the R-Tree | paper access original implementation |
| R-Variant | Adapted form of original R-Tree with configurable split and insert algorithms (e.g., R*-Tree). N. Beckmann, H.-P. Kriegel, R. Schneider, and B. Seeger, The R*-Tree: An efficient and robust access method for points and rectangles in SIGMOD. ACM, 1990, pp. 322-331. | paper access |
| k-d Tree | Original paper: J.L.Bentley, Multidimensional binary search trees used for associative searching, Comm. ACM, 1975 Original implementation from Simon Levy's software archive | paper access original implementation |
| M-tree | Original paper: P. Ciaccia et al., M-tree: An Efficient Access Method for Similarity Search in Metric Spaces, VLDB, 1997 | paper access |
One of our aims is to maintain an extensible framework so that other researcher can contribute to it and use it for their specific purposes. A central aspect of this extensibility is the possibility to add new index structures to the framework. To this end, an API exists that has to be implemented for each new index structure. You can find a documentation (JavaDoc style) of this interface at AIndexStructure -- Documentation
For improving the extensiblety of the framework, we implemented some advanced features. These features are not needed to perform tests with the framework but are useful to extend the user experience.
C++ Handler. Since we are aware that many existing index structure implementations are written in C++ and we also want to support evaluations using these implementations. We decided to extend the framework with an interface to include and evaluate existing C++ implementations. Find the details here.
Visualisation extension. To improve the user experience for understanding different index structures, we offer visualisation extensions for showing the partition done by different index structures.
Extension to R. With our framework, we will also evaluate the performace impact of complex stoachstic distributed data on the different index structres. Since, we are aware that there are a lot of programming languages to create stochastic distributed data, we extended our framework with an extension to R.
The current version of QuEval can be downloaded as ZIP-compressed archive: Download page or use the direct zip file link. After downloading the file, extract it to your file system. Afterwards, proceed as follows (where QUEVAL_PATH denotes the main directory of the extracted framework):
| Scenario description | #Dimensions | #Points in data set | Further information/paper reference | Link(s) |
|---|---|---|---|---|
| Use case 1: Forensic evidences (handwriting samples) | ||||
| Real-world data | 16 | 10,992 | F. Alimoglu and E. Alpaydin, Methods of combining multiple classifiers based on different representations for pen-based handwriting recognition in ICDAR. IEEE, 1997, pp. 637-640. | paper access uniform data Gaussian data real-world data |
| Uniform data | Produced by internal data generator | |||
| Gaussian data | Produced by extension to R | |||
| Use case 2: Sensor parameter optimization | ||||
| Real-world data | 43 | 411,961 | T. Kiertscher, R. Fischer, and C. Vielhauer, Latent fingerprint detection using a spectral texture feature in MMSec. ACM, 2011, pp. 27-32. | paper access uniform data Gaussian data real-world data |
| Unifom data | Produced by internal data generator | |||
| Gaussian data | Produced by extension to R | |||
| Use case 3: Low populated high-dimensional database | ||||
| Real-world data | 50 | 130,064 | B. P. Roe, H.-J. Yang, J. Zhu, Y. Liu, I. Stancu, and G. McGregor, Boosted decision trees as an alternative to artificial neural networks for particle identification. NIMPA, vol. 543, no. 2-3, pp. 577-584, 2005. | paper access uniform data Gaussian data real-world data |
| Unifom data | Produced by internal data generator | |||
| Gaussian data | Produced by extension to R | |||
| Use case 4: Dense populated high-dimensional database | ||||
| Real-world data | 51 | 3,850,505 | A. Reiss and D. Stricker, Creating and benchmarking a new dataset for physical activity monitoring. PETRA, pp. 40:140:8, 2012. | paper access compressed data (rar) |
| Unifom data | Produced by internal data generator | |||
| Gaussian data | Produced by extension to R | |||
Veit Köppen, Martin Schäler, and Reimar Schröter. Toward variability management to tailor high-dimensional index implementations . In International Conference on Research Challenges in Information Science (RCIS). IEEE, 2014 - to appear.
Martin Schäler, Alexander Grebhahn, Reimar Schröter, Sandro Schulze, Veit Köppen, and Gunter Saake. QuEval: Beyond high-dimensional indexing à la carte . In Proc Int' Conf. on Very Large Databases (VLDB), pages 1654–1665. VLDB Endowment, 2013.
David Broneske, Martin Schäler, and Alexander Grebhahn. Extending an Index-Benchmarking Framework with Non-Invasive Visualization Capability . In Workshop on Information Systems in Digital Engineering (ISDE), BTW-Workshops, pages 151–160. Köllen-Verlag, 2013.
Alexander Grebhahn, Martin Schäler, Veit Köppen, and Gunter Saake. Privacy-Aware Multidimensional Indexing . In 15. GI-Fachtagung Datenbanksysteme für Business, Technologie und Web (BTW), pages 133–147. Köllen-Verlag, 2013.
Alexander Grebhahn, David Broneske, Martin Schäler, Reimar Schröter, Veit Köppen, and Gunter Saake. Challenges in finding an appropriate multi-dimensional index structure with respect to specific use cases . In Proceedings of the 24th GI-Workshop "Grundlagen von Datenbanken 2012", pages 77–82. CEUR-WS, 2012. urn:nbn:de:0074-850-4.
Jan Hentschel, Thomas Meyer, Thomas Rommel. Trying to outperform a well-known index with a sequential scan . In EDBT/ICDT Workshops 2013 pages 349-356.
Martin Schäler, Sandro Schulze, Alexander Grebhahn, Veit Köppen, Andreas Lübcke, and Gunter Saake (Hrsg.). Techniken zur forensischen Datenhaltung - Ausgewählte studentische Beiträge . Collection FIN-05-2012, University of Magdeburg, Germany, October 2012. In German.
Tim Hering. Parallelization of K-D Trees for kNN-queries in main memory. BTW Studierendenprogramm (Students program), 2013, Köllen-Verlag.
Sarah Heckel. Optimierung der Exact-Match Anfrage eines Lokal Sensitiven Hashverfahrens. BTW Studierendenprogramm (Students program), 2013, Köllen-Verlag, In German.
QuEval is developed mainly at the University of Magdeburg, Germany. It is open source and we are currently working on the first release so that everybody who is interested can extend/improve it. For information about the project, technical questions and bug reports: please contact the development team via Martin Schäler.
Project members:Copyright Notice: This material is presented to ensure timely dissemination of scholarly and technical work. Copyright and all rights therein are retained by authors or by other copyright holders. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright. In most cases, these works may not be reposted without the explicit permission of the copyright holder.